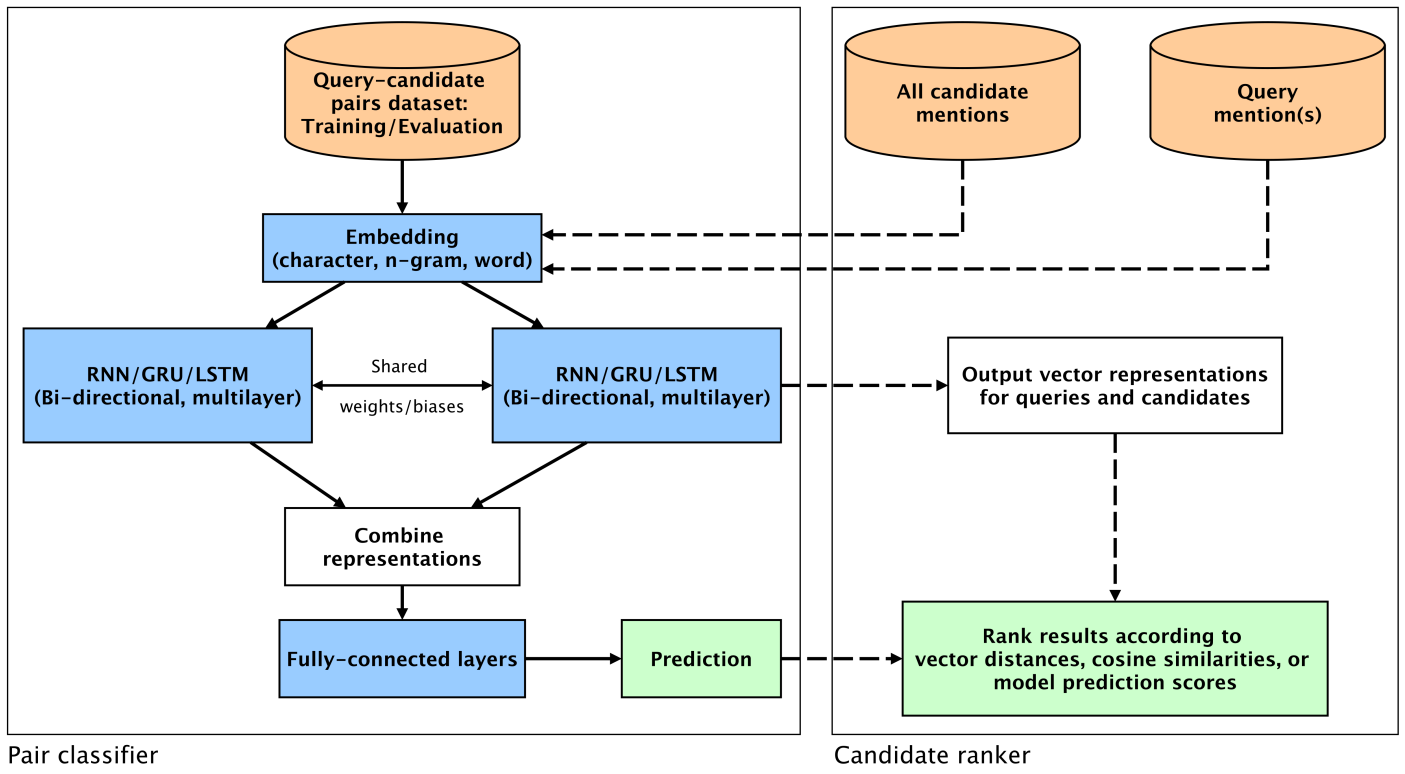
How do you match "Newe Yorke" to "New York" or recognize that "Londan" (from a poorly OCR'd document) refers to "London"? DeezyMatch addresses fuzzy string matching through deep learning with transfer learning capabilities, particularly valuable when training data is scarce. The architecture has two components: a pair classifier (left) that trains neural networks to recognize similar strings with learnable parameters (blue) that can be fine-tuned for new domains, and a candidate ranker (right) that generates vector representations and ranks matches using similarity metrics like cosine distance. By enabling transfer learning, DeezyMatch handles the messy realities of historical text analysis, where spelling variations, OCR errors, and limited annotated examples are the norm rather than the exception.
Abstract
We present DeezyMatch, a free, open-source software library written in Python for fuzzy string matching and candidate ranking. Its pair classifier supports various deep neural network architectures for training new classifiers and for fine-tuning a pretrained model, which paves the way for transfer learning in fuzzy string matching. This approach is especially useful where only limited training examples are available. The learned DeezyMatch models can be used to generate rich vector representations from string inputs. The candidate ranker component in DeezyMatch uses these vector representations to find, for a given query, the best matching candidates in a knowledge base. It uses an adaptive searching algorithm applicable to large knowledge bases and query sets. We describe DeezyMatch’s functionality, design and implementation, accompanied by a use case in toponym matching and candidate ranking in realistic noisy datasets.
Keywords: fuzzy string matching, deep learning, neural networks, transfer learning, toponym matching, candidate ranking
Citation
Please cite this work as:
Kasra Hosseini, Federico Nanni, Mariona Coll Ardanuy. "DeezyMatch: A Flexible Deep Learning Approach to Fuzzy String Matching". Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (2020). https://doi.org/10.18653/v1/2020.emnlp-demos.9
Or use the BibTeX citation:
@inproceedings{hosseini-etal-2020-deezymatch,
title = "{D}eezy{M}atch: A Flexible Deep Learning Approach to Fuzzy String Matching",
author = "Hosseini, Kasra and
Nanni, Federico and
Coll Ardanuy, Mariona",
editor = "Liu, Qun and
Schlangen, David",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-demos.9/",
doi = "10.18653/v1/2020.emnlp-demos.9",
pages = "62--69"
}