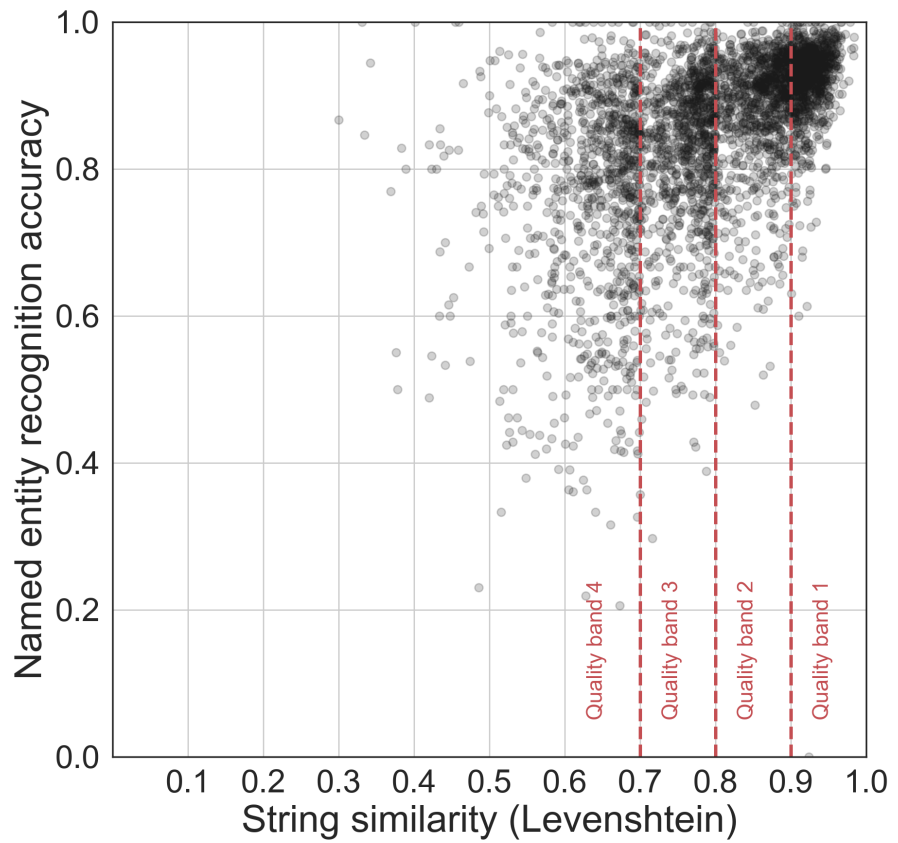
Growing volumes of historical documents are being digitized through optical character recognition (OCR), yet the impact of OCR errors on downstream NLP tasks remains only partially understood. This study systematically quantifies how OCR quality affects popular, out-of-the-box NLP tools across six tasks: sentence segmentation, named entity recognition, dependency parsing, information retrieval, topic modeling, and language model fine-tuning. The figure shows named entity recognition accuracy declining as OCR quality decreases (measured by Levenshtein similarity to human-corrected text), with each point representing one article. Results reveal that some tasks are more robust to OCR errors than others, with certain analyses suffering irredeemable degradation, providing preliminary guidelines for choosing appropriate methods when working with OCR-generated historical texts.
Abstract
A growing volume of heritage data is being digitized and made available as text via optical character recognition (OCR). Scholars and libraries are increasingly using OCR-generated text for retrieval and analysis. However, the process of creating text through OCR introduces varying degrees of error to the text. The impact of these errors on natural language processing (NLP) tasks has only been partially studied. We perform a series of extrinsic assessment tasks - sentence segmentation, named entity recognition, dependency parsing, information retrieval, topic modelling and neural language model fine-tuning - using popular, out-of-the-box tools in order to quantify the impact of OCR quality on these tasks. We find a consistent impact resulting from OCR errors on our downstream tasks with some tasks more irredeemably harmed by OCR errors. Based on these results, we offer some preliminary guidelines for working with text produced through OCR.
Keywords: Optical Character Recognition, OCR, Digital Humanities, Natural Language Processing, NLP, Information Retrieval
Citation
Please cite this work as:
Daniel van Strien, Kaspar Beelen, Mariona Coll Ardanuy, Kasra Hosseini, Barbara McGillivray, Giovanni Colavizza. "Assessing the Impact of OCR Quality on Downstream NLP Tasks". Proceedings of the 12th International Conference on Agents and Artificial Intelligence - Volume 1: ARTIDIGH (2020). https://doi.org/10.5220/0009169004840496
Or use the BibTeX citation:
@conference{artidigh20,
author={Daniel {van Strien} and Kaspar Beelen and Mariona Coll Ardanuy and Kasra Hosseini and Barbara McGillivray and Giovanni Colavizza},
title={Assessing the Impact of OCR Quality on Downstream NLP Tasks},
booktitle={Proceedings of the 12th International Conference on Agents and Artificial Intelligence - Volume 1: ARTIDIGH},
year={2020},
pages={484-496},
publisher={SciTePress},
organization={INSTICC},
doi={10.5220/0009169004840496},
isbn={978-989-758-395-7},
issn={2184-433X}
}