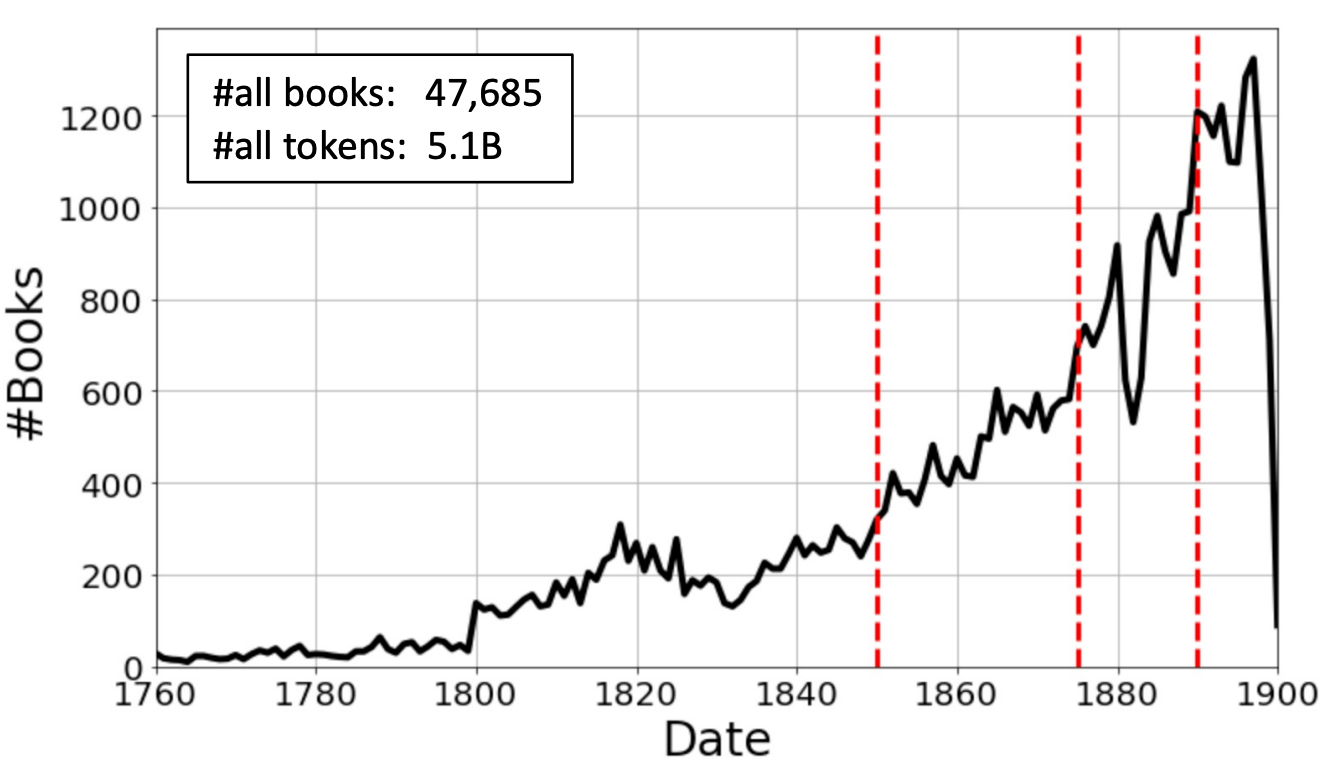
Modern NLP models trained on contemporary text struggle with historical language because words shift meanings, new terms emerge, and grammatical patterns evolve. This paper addresses the challenge by training four types of neural language models specifically on nineteenth-century English: 47,685 books spanning 1760-1900, totaling approximately 5.1 billion tokens. The models range from static embeddings (word2vec and fastText) to contextualized models (BERT and Flair), with red dashed lines marking temporal boundaries for time-sliced training. This temporal slicing enables models tailored to specific historical periods, capturing how "railway" meant nothing in 1760 but dominated discourse by 1850. The resulting models consistently improve performance on downstream tasks when analyzing historical documents, demonstrating that language models must be historically situated to work effectively.
Abstract
We present four types of neural language models trained on a large historical dataset of books in English, published between 1760-1900 and comprised of ~5.1 billion tokens. The language model architectures include static (word2vec and fastText) and contextualized models (BERT and Flair). For each architecture, we trained a model instance using the whole dataset. Additionally, we trained separate instances on text published before 1850 for the two static models, and four instances considering different time slices for BERT. Our models have already been used in various downstream tasks where they consistently improved performance. In this paper, we describe how the models have been created and outline their reuse potential.
Keywords: neural language models, historical text, word2vec, fastText, BERT, Flair, nineteenth-century English
Citation
Please cite this work as:
Kasra Hosseini, Kaspar Beelen, Giovanni Colavizza, Mariona Coll Ardanuy. "Neural Language Models for Nineteenth-Century English". arXiv preprint (2021). https://openhumanitiesdata.metajnl.com/articles/10.5334/johd.48
Or use the BibTeX citation:
@misc{hosseini2021neurallanguagemodelsnineteenthcentury,
title={Neural Language Models for Nineteenth-Century English},
author={Kasra Hosseini and Kaspar Beelen and Giovanni Colavizza and Mariona Coll Ardanuy},
year={2021},
eprint={2105.11321},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2105.11321}
}