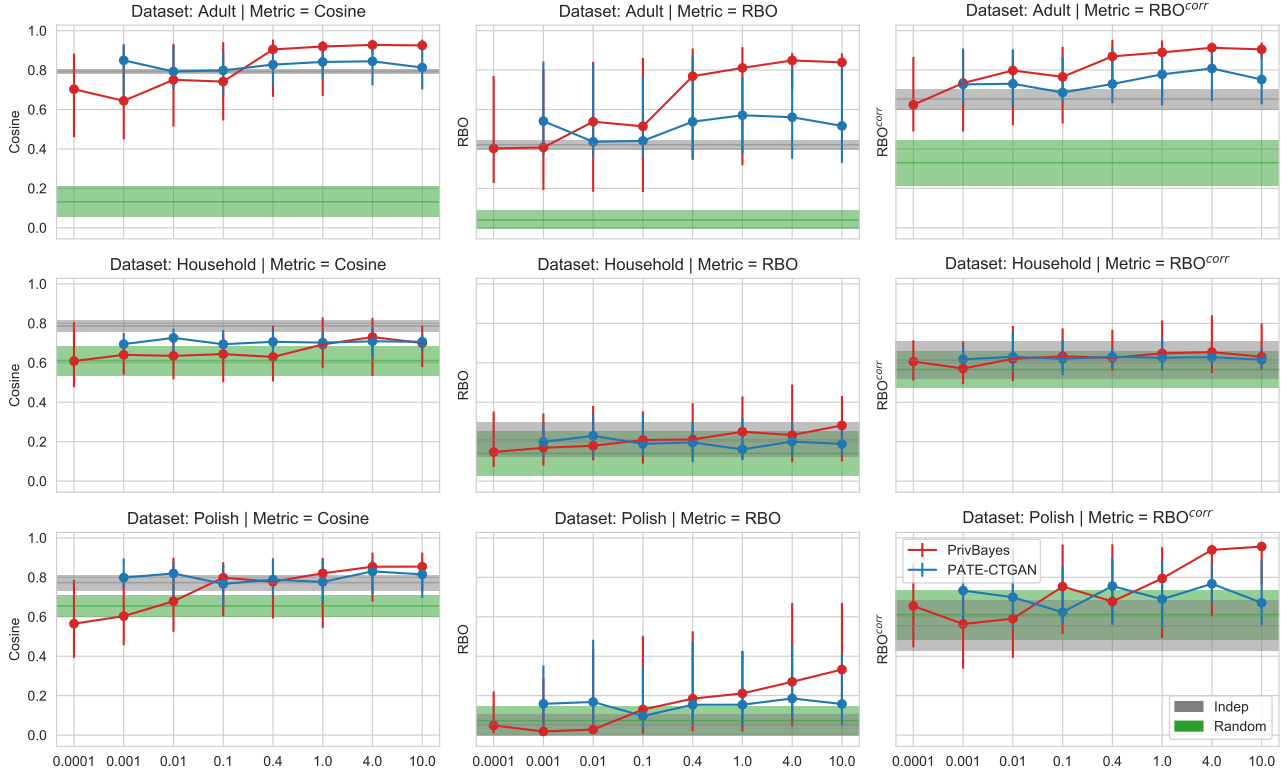
Synthetic data promises to unlock sensitive datasets for early-stage analysis while preserving privacy - but can it reliably tell you which features matter? This paper reveals a cautionary finding: differentially-private synthetic data struggles to preserve feature importance rankings across real-world datasets. While the Adult dataset shows promising similarity at higher epsilon values, the Household and Polish datasets tell a different story. The results demonstrate that without compromising privacy guarantees (epsilon > 0.4), synthetic data often performs no better than naive baselines, with high variance across runs. This has critical implications for using synthetic data in the exploratory phase of machine learning workflows in sensitive domains like healthcare and finance.
Abstract
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
Citation
Please cite this work as:
Oscar Giles, Kasra Hosseini, Grigorios Mingas, Oliver Strickson, Louise Bowler, Camila Rangel Smith, Harrison Wilde, Jen Ning Lim, Bilal Mateen, Kasun Amarasinghe, Rayid Ghani, Alison Heppenstall, Nik Lomax, Nick Malleson, Martin O'Reilly, Sebastian Vollmer. "Faking feature importance: A cautionary tale on the use of differentially-private synthetic data". arXiv preprint (2022).
Or use the BibTeX citation:
@misc{giles2022fakingfeatureimportancecautionary,
title={Faking feature importance: A cautionary tale on the use of differentially-private synthetic data},
author={Oscar Giles and Kasra Hosseini and Grigorios Mingas and Oliver Strickson and Louise Bowler and Camila Rangel Smith and Harrison Wilde and Jen Ning Lim and Bilal Mateen and Kasun Amarasinghe and Rayid Ghani and Alison Heppenstall and Nik Lomax and Nick Malleson and Martin O'Reilly and Sebastian Vollmer},
year={2022},
eprint={2203.01363},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2203.01363}
}