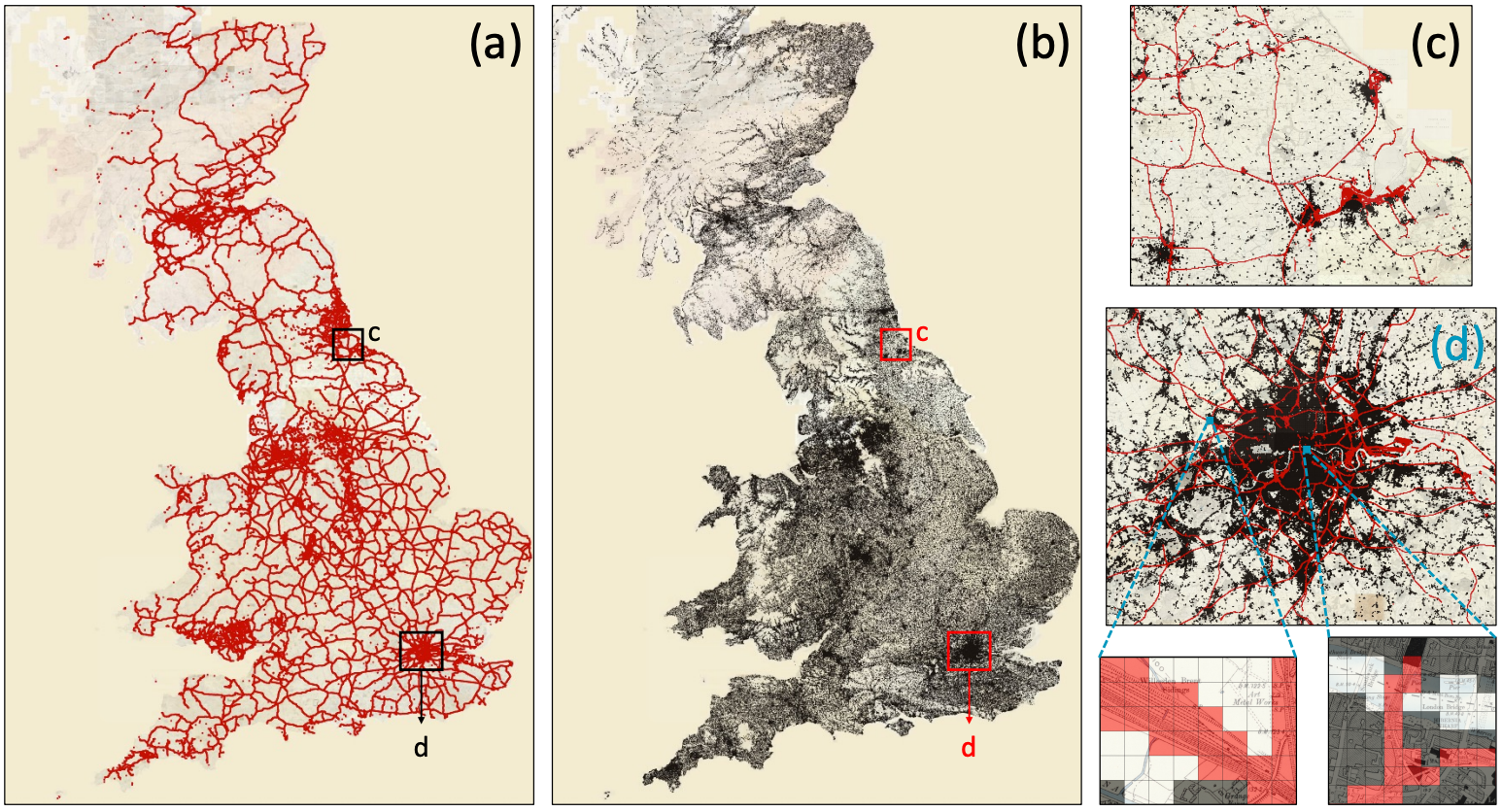
Historical maps contain rich information about past landscapes, but extracting data from thousands of maps has traditionally required painstaking manual annotation. MapReader automates this process using computer vision, making large-scale map analysis accessible to users without deep learning expertise. The pipeline divides maps into patches (see insets), trains neural networks to recognize visual features like railways (a, shown in red in c,d) and buildings (b, shown in black in c,d), then reconstructs predictions across entire map sheets. Applied to approximately 16,000 nineteenth-century British Ordnance Survey maps (roughly 30.5 million patches), MapReader transforms visual cartographic information into structured, machine-readable data. The resulting datasets can be queried spatially, analyzed for patterns, and linked to other historical sources, enabling researchers to ask questions at scales previously impossible.
Abstract
We present MapReader, a free, open-source software library written in Python for analyzing large map collections. MapReader allows users with little computer vision expertise to i) retrieve maps via web-servers; ii) preprocess and divide them into patches; iii) annotate patches; iv) train, fine-tune, and evaluate deep neural network models; and v) create structured data about map content. We demonstrate how MapReader enables historians to interpret a collection of ≈16K nineteenth-century maps of Britain (≈30.5M patches), foregrounding the challenge of translating visual markers into machine-readable data. We present a case study focusing on rail and buildings. We also show how the outputs from the MapReader pipeline can be linked to other, external datasets. We release ≈62K manually annotated patches used here for training and evaluating the models.
Keywords: classification, computer vision, deep learning, digital libraries and archives, historical maps, supervised learning
Citation
Please cite this work as:
Kasra Hosseini, Daniel C. S. Wilson, Kaspar Beelen, Katherine McDonough. "MapReader: a computer vision pipeline for the semantic exploration of maps at scale". Proceedings of the 6th ACM SIGSPATIAL International Workshop on Geospatial Humanities (2022). https://doi.org/10.1145/3557919.3565812
Or use the BibTeX citation:
@inproceedings{10.1145/3557919.3565812,
author = {Hosseini, Kasra and Wilson, Daniel C. S. and Beelen, Kaspar and McDonough, Katherine},
title = {MapReader: a computer vision pipeline for the semantic exploration of maps at scale},
year = {2022},
isbn = {9781450395335},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3557919.3565812},
doi = {10.1145/3557919.3565812},
abstract = {We present MapReader, a free, open-source software library written in Python for analyzing large map collections. MapReader allows users with little computer vision expertise to i) retrieve maps via web-servers; ii) preprocess and divide them into patches; iii) annotate patches; iv) train, fine-tune, and evaluate deep neural network models; and v) create structured data about map content. We demonstrate how MapReader enables historians to interpret a collection of ≈16K nineteenth-century maps of Britain (≈30.5M patches), foregrounding the challenge of translating visual markers into machine-readable data. We present a case study focusing on rail and buildings. We also show how the outputs from the MapReader pipeline can be linked to other, external datasets. We release ≈62K manually annotated patches used here for training and evaluating the models.},
booktitle = {Proceedings of the 6th ACM SIGSPATIAL International Workshop on Geospatial Humanities},
pages = {8--19},
numpages = {12},
keywords = {classification, computer vision, deep learning, digital libraries and archives, historical maps, supervised learning},
location = {Seattle, Washington},
series = {GeoHumanities '22}
}