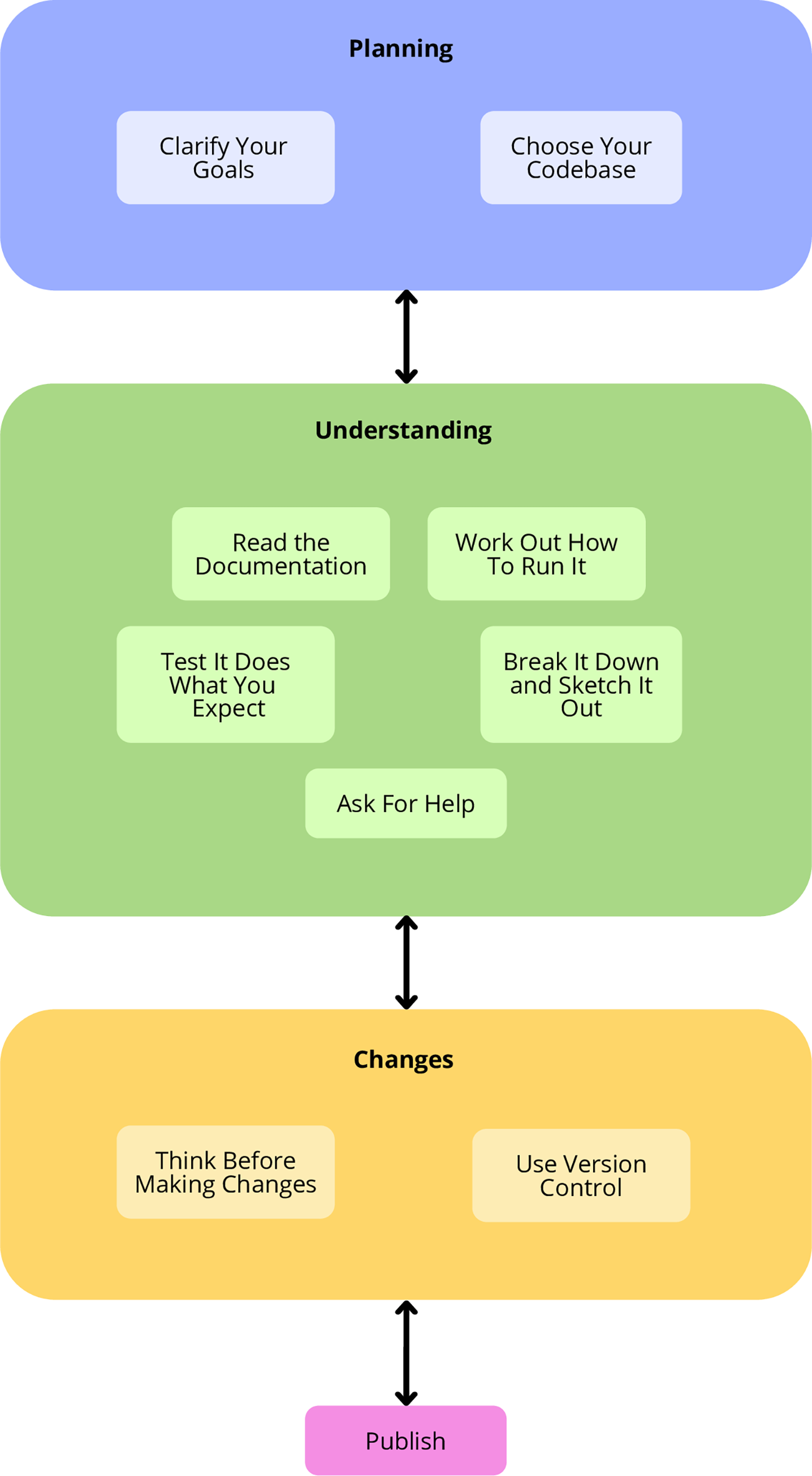
Abstract
Every time that you use a computer, you are using someone else’s code, whether that be an operating system, a word processor, a web application, research tools, or simply code snippets. Almost all code has some bugs and errors. In day to day life, these bugs are usually not too important or at least obvious when they do happen (think of an operating system crashing). However, in research, there is a perfect storm that makes working with other people’s code particularly challenging - research needs to be correct and accurate, researchers often use niche and non-commercial tools that are not built with best software practices, bugs can be subtle and hard to detect, and researchers have time pressures to get things done quickly. It is no surprise then that working with other people’s code is a common frustration for researchers and is even considered a rite of passage.
There are a wealth of resources addressing how to write better code in academia, including PLOS ONE “Ten Simple Rules” articles on reproducibility, documentation, and writing open-source software. And there are calls for improving research reproducibility by publishing code and ensuring it is reusable. However, the inverse problem - working with other people’s code in research - does not receive as much attention. In industry, there are some resources for working with legacy code (“legacy code” essentially translates to “other people’s code”). While industry software development practices are useful, they often cannot be applied blindly to research software development and instead need to be adapted. Therefore, our approach is to bring together and integrate lessons from industry, existing literature, and the research experiences of the authors and their colleagues.
The rules in this article will be useful for academic researchers at all levels, from students to professors. Our focus is on pragmatic research efficiency, as opposed to absolute best practices that may introduce unrealistic time burdens. The rules are informed but opinionated, and as such, we encourage readers to use the rules as a starting point to think for themselves and do what works for them. Overall, if the reader can take one useful idea or thought from this article, then we will consider it successful.
Keywords: software engineering, research methods, legacy code, code reuse, reproducibility