Summary
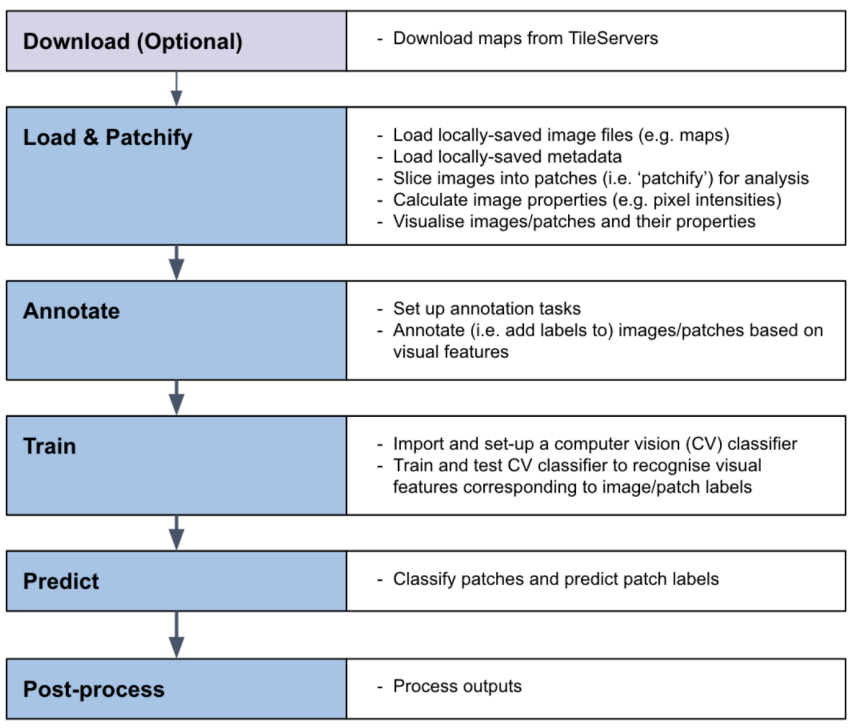
MapReader is an interdisciplinary software library for processing digitized maps and other types of images with two tasks: patch classification and text spotting. Patch classification works by ‘patching’ images into small, custom-sized cells which are then classified according to the user’s needs. Text spotting detects and recognizes text. MapReader offers a flexible pipeline which can be used both for manual annotation of small datasets as well as for computer-vision-based inference of large collections. As an example, in one study, we annotated 62,020 patches, trained a suite of computer vision models and performed model inference on approximately 30.5 million patches.
MapReader’s approach was inspired by methods in biomedical imaging, which were adapted for use by historians, and it is suitable for a wide range of applications in image analysis: it has, for example, been applied to an image classification problem in plant phenotype research. This cross-pollination between the humanities and the natural sciences was made possible by the open and reproducible research methods at the heart of MapReader.
MapReader pioneers a methodological shift in how historians interact with maps as primary sources. Sustained engagement with big collections of maps rarely moves beyond analysis of cartographic history. To change this, MapReader encourages historians to reflect on the content of maps and is designed to facilitate linking datasets representing visual map content with other historical geospatial data to enable spatial historical research.
In this paper, we present the MapReader release at the conclusion of the Living with Machines project, which supported the initial development of the software and associated historical research. This release represents the culmination of extensive work to improve MapReader’s usability among historians, especially through clear documentation and tutorials.
Keywords: computer vision, digital humanities, historical maps, image classification, text recognition, open source software, patch classification