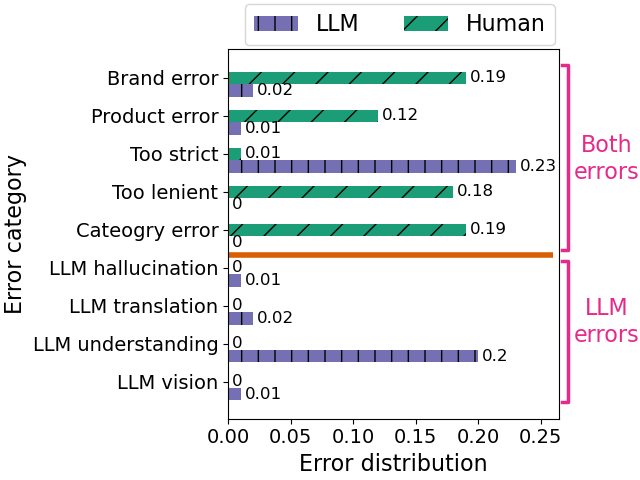
In this paper, we compare LLM-based annotations with human annotations on large-scale product retrieval evaluation, revealing striking differences in error patterns. Analyzing hard disagreements shows that humans and LLMs make complementary errors: humans frequently misjudge brands, products, and categories (often due to annotation fatigue), while LLMs tend to be overly strict or misunderstand query intent (e.g., interpreting brand name "On Vacation" literally). This complementary error profile demonstrates that LLMs excel at handling bulk annotation work for common queries, while human expertise remains valuable for nuanced cases involving style and trends.
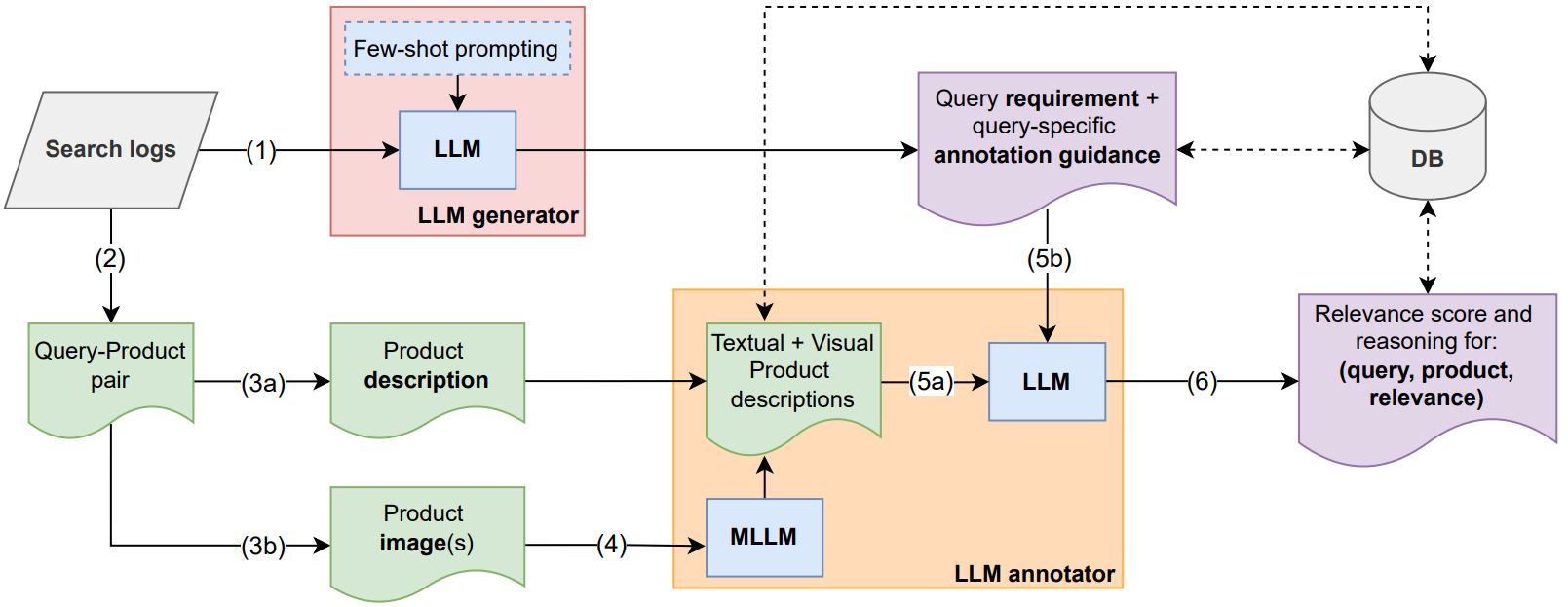
We propose a framework that leverages multimodal LLMs to generate query-specific annotation guidelines and conduct relevance assessments for large-scale product retrieval evaluation. The framework achieves comparable quality to human annotations while evaluating 20,000 query-product pairs in ~20 minutes (vs. weeks for humans) at 1,000x lower cost. The complete pipeline includes: (1) query and product retrieval from search logs, (2) LLM-generated query-specific annotation guidelines, (3) multimodal processing combining text and images, (4) vision model-generated image descriptions, and (5) LLM-based relevance annotation. The orange rectangle highlights where a single Multimodal LLM could streamline the process by directly processing both images and text.
Abstract
Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated on a large e-commerce platform, achieves comparable quality to human annotations, significantly reduces time and cost, enables rapid problem discovery, and provides an effective solution for scalable, production-level quality control.
Keywords: Relevance Assessment, Large Language Models, LLM, Information Retrieval, System Evaluation, E-commerce Search, NLP Applications
Citation
Please cite this work as:
Kasra Hosseini, Thomas Kober, Josip Krapac, Roland Vollgraf, Weiwei Cheng, Ana Peleteiro Ramallo. "Retrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation". Advances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025 (2025). https://doi.org/10.1007/978-3-031-88708-6_10
Or use the BibTeX citation:
@InProceedings{10.1007/978-3-031-88708-6_10,
author="Hosseini, Kasra
and Kober, Thomas
and Krapac, Josip
and Vollgraf, Roland
and Cheng, Weiwei
and Peleteiro Ramallo, Ana",
editor="Hauff, Claudia
and Macdonald, Craig
and Jannach, Dietmar
and Kazai, Gabriella
and Nardini, Franco Maria
and Pinelli, Fabio
and Silvestri, Fabrizio
and Tonellotto, Nicola",
title="Retrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation",
booktitle="Advances in Information Retrieval",
year="2025",
publisher="Springer Nature Switzerland",
address="Cham",
pages="149--163",
abstract="Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated on a large e-commerce platform, achieves comparable quality to human annotations, significantly reduces time and cost, enables rapid problem discovery, and provides an effective solution for scalable, production-level quality control.",
isbn="978-3-031-88708-6"
}