Note: Most of the content in this blogpost was previously published on the Zalando Engineering Blog.
We introduce a novel approach to large-scale product retrieval evaluation using Multimodal Large Language Models (MLLMs). Evaluated on 20,000 examples, our method shows how MLLMs can help automate the relevance assessment of retrieved products, achieving levels of accuracy comparable to human annotators and enabling scalable evaluation for high-traffic e-commerce platforms.
Our contributions include:
- A multimodal LLM-based evaluation framework for large-scale product retrieval systems that utilizes LLMs to (i) generate context-specific annotation guidelines and (ii) conduct relevance assessments.
- Performance evaluation against human annotations on real-world production search queries in a multilingual setting, with analysis of different types of errors that humans and LLMs tend to make.
- Demonstration of cost-effectiveness and efficiency for conducting large-scale evaluations, comparing different types of LLMs including GPT-4o, GPT-4 Turbo and GPT-3.5 Turbo.
Why Evaluate Product Retrieval at Scale?
Search functionality is a fundamental component of e-commerce platforms, with the objective of finding the most relevant products in a dynamic product database. Customers using search often exhibit a higher intent to find specific products, leading to greater engagement and conversion rates. However, they may struggle to articulate their needs in a search query. Even if they do express their intent clearly, information retrieval systems and search engines might fail to interpret it correctly, resulting in irrelevant search results.
Evaluating product retrieval systems on a large scale in a multilingual setting and for a diverse set of customer queries is an intricate but essential task for maintaining a high-quality user experience and driving business success. Traditionally, the quality of these results is measured through human relevance assessments, which require substantial time and resources.
Our paper proposes a scalable solution: a framework that integrates Multimodal LLMs (i) to generate context-specific annotation guidelines and (ii) to conduct relevance assessments. By using MLLMs that analyze both text and images, we enable a high level of semantic accuracy in evaluating query-product relevance without the need for extensive human input.
Retrieve, Annotate, Evaluate, Repeat
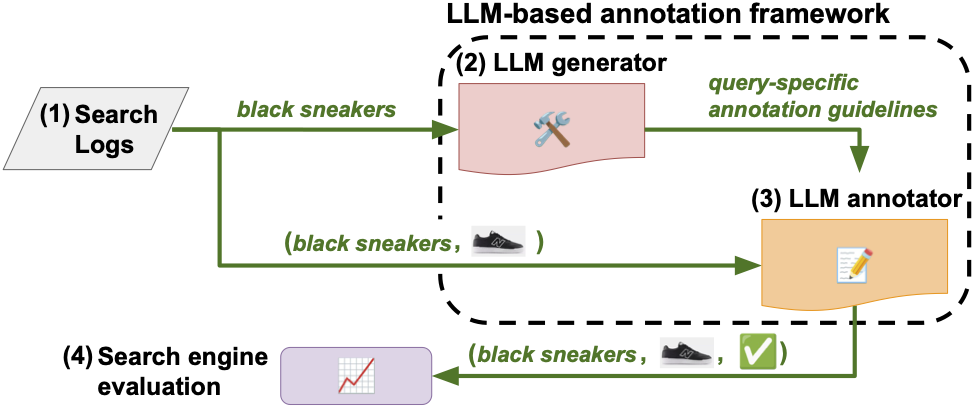
Our framework, built for efficiency and scalability, is structured as follows:
- Query extraction: query-product pairs are extracted from search logs for evaluation.
- Guideline generation: for each query, an LLM generates custom annotation guidelines, setting detailed criteria for relevance.
- Multimodal annotation: MLLMs assign relevancy scores to the search results based on both textual and visual descriptions, classifying each result as “highly relevant”, “acceptable substitute”, or “irrelevant”.
- Evaluation and storage: each labeled pair is stored for continuous retrieval system evaluation and comparison across different configurations.
The framework’s modular design allows for caching and parallel processing, enabling evaluations to scale efficiently to support multiple search engines and to accommodate updates to retrieval algorithms.
Technical Implementation
Our framework leverages several key technical optimizations for efficiency:
- Chain-of-thought prompting: The LLM annotator uses chain-of-thought reasoning to provide transparent explanations for each relevance judgment, improving both accuracy and interpretability.
- Intelligent caching: Query-specific guidelines are cached and reused across multiple products for the same query, significantly reducing API calls and costs.
- Parallel processing: The system processes multiple query-product pairs concurrently through API-based deployment, enabling rapid evaluation at scale.
- Modular architecture: Each component (guideline generator, annotator, evaluator) operates independently, allowing for easy updates and A/B testing of different configurations.
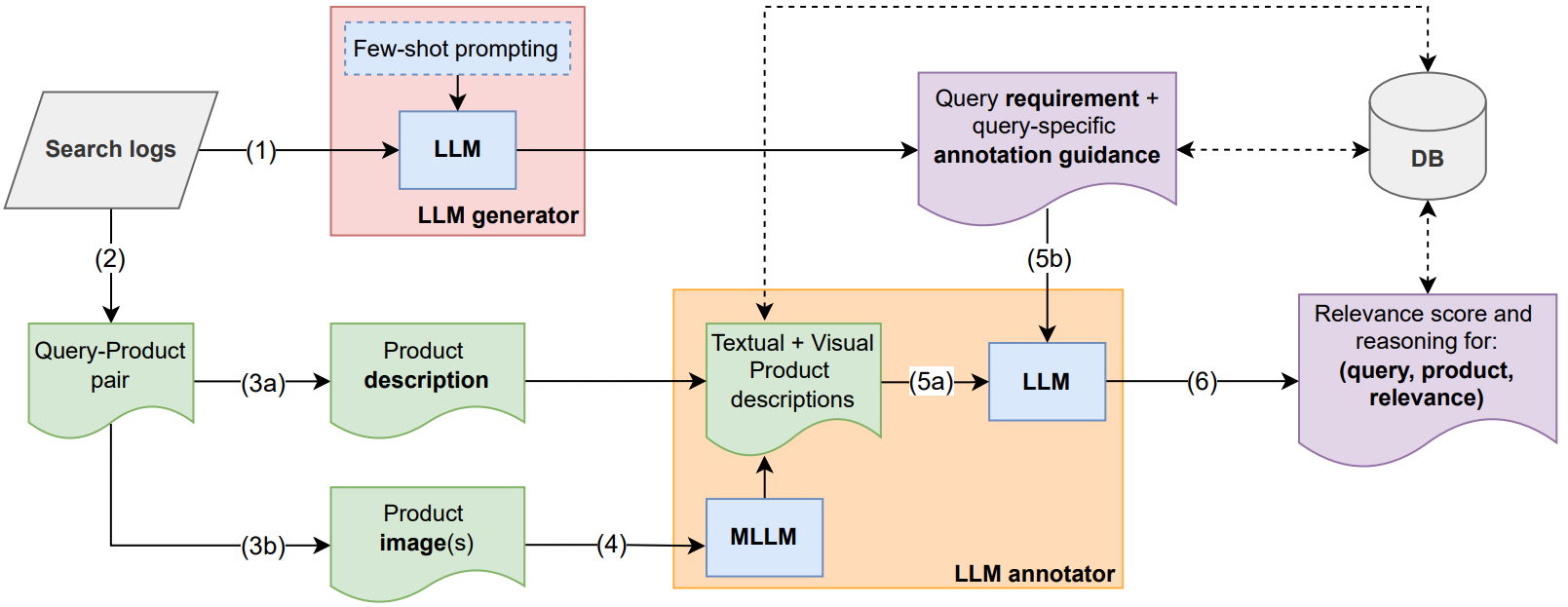
Detailed Framework Architecture
The figure below provides a detailed view of our multimodal LLM-powered evaluation framework, showing all the main components and data flow through the system.
Multimodal LLM-powered Relevance Assessment
We assess the performance of different types of LLMs in relevance assessment, including GPT-4o, GPT-4 Turbo and GPT-3.5 Turbo. By leveraging Multimodal LLMs (MLLMs) that analyze both text and images, our framework enables a high level of semantic accuracy in evaluating query-product relevance at scale, minimizing the need for extensive human input.
Dataset and Evaluation Methodology
To rigorously validate our approach, we conducted experiments on a comprehensive dataset comprising 500 queries (250 in English and 250 in German) extracted from real production search logs. For each query, we evaluated 20 products, resulting in 10,000 query-product pairs. The queries were selected using stratified sampling to ensure diverse coverage of different query types and complexity levels. The annotation process consisted of three phases: a pilot study to refine guidelines, the main annotation study with two independent human annotator groups (A1 and A2), and a tiebreaker phase to resolve disagreements.
We compare agreements based on (i) matching either A1 or A2 and (ii) inter annotator agreement between human annotators (A1 vs. A2) and between LLMs and the human majority vote. Results are reported separately for English and German. For human annotations, we report the total time and cost.
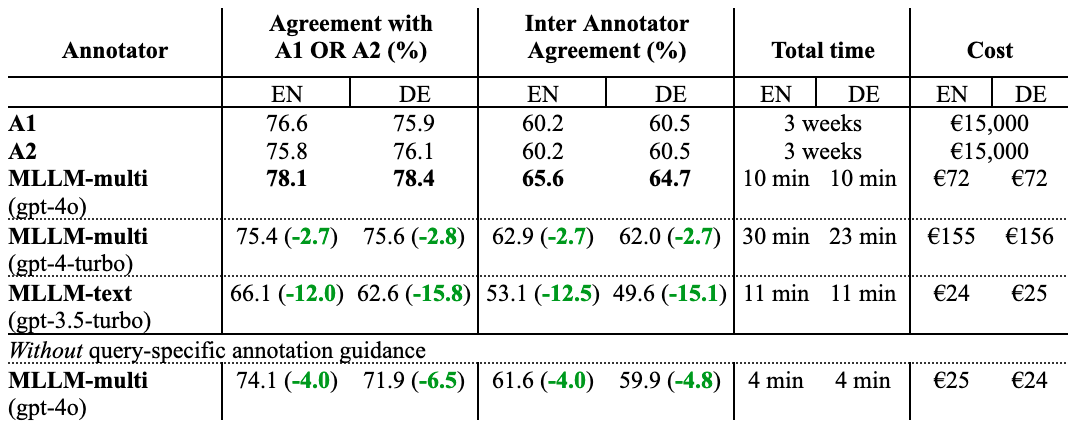
While all three LLM models show strong performance, GPT-4o and GPT-4 Turbo achieve higher agreement with human annotators (~78-82%) compared to GPT-3.5 Turbo (~74-77%). The choice between models involves balancing annotation quality against cost and speed considerations. Notably, even human annotators only agree ~82% of the time (A1 vs. A2), highlighting the inherently subjective nature of relevance assessment. Our LLM-based approach achieves comparable agreement rates, demonstrating that it captures this subjective judgment as well as human experts.
Our ablation study confirms that query-specific guidelines generated by the LLM generator improve annotation quality by approximately 5% compared to using generic guidelines, validating our two-step approach of separate guideline generation and annotation phases.
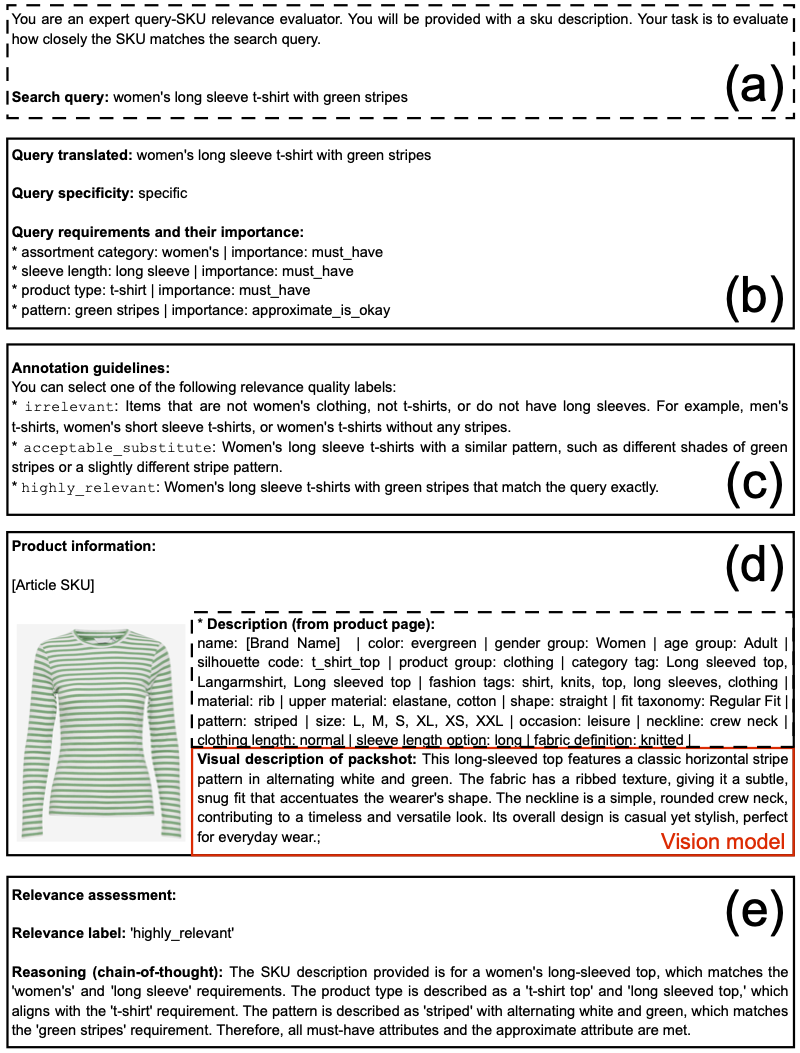
Evaluation Steps for an Example Query
Figure 2 demonstrates the structured process of our evaluation framework with the example query “women’s long sleeve t-shirt with green stripes” in panel (a). The LLM identifies and prioritizes four query requirements: “assortment category”; “sleeve length”; “product type” and “pattern”, with assigned importance levels, as shown in panel (b). Using this information, query-specific annotation guidelines are generated in panel (c) to provide tailored descriptions for three relevance labels: “irrelevant”, “acceptable substitute” and “highly relevant”.
Panel (d) illustrates an example product and its attributes, with the relevance label “highly relevant” assigned in panel (e) based on LLM-guided reasoning. The entire content displayed in this figure is generated by Multimodal LLMs, except for panel (a), the packshot in panel (d), and the black dashed rectangle also in panel (d). However, within the attributes shown in panel (d), the “visual description of packshot”, highlighted by a red rectangle, is generated by a vision model (here: GPT-4o).
Key Findings and Benefits
Our method, validated through deployment on Zalando’s large e-commerce platform, demonstrates comparable quality to human annotations. This approach offers several advantages:
- Cost efficiency: MLLM-based assessments are up to 1,000 times cheaper than human labor, resulting in substantial resource savings.
- Speed: The pipeline can assess 20,000 query-product pairs in around 20 minutes, compared to the weeks needed for human annotators.
- Multilingual adaptability: The framework supports multiple languages, essential for e-commerce platforms operating in diverse markets.
- Error analysis: MLLMs demonstrated lower rates of common human errors, such as brand mismatches, which are often caused by annotation fatigue, making MLLMs a reliable solution for repetitive assessment tasks.
Human versus LLM Error Analysis
We compare the LLM-based annotations to human annotations on a dataset collected from live traffic and find that while humans and LLMs approximately make the same amount of errors, the respective error distributions are very different. To understand failure modes in depth, we analyzed the 15% of annotations where humans and LLMs had hard disagreements (more than 1 label difference in their relevance assessments).
For example, the majority of human errors are on (i) brands (e.g. query asks for an Adidas sneaker, retrieved product is from another brand, yet humans would annotate it as relevant), (ii) products and (iii) categories.
On the other hand, LLMs barely made these errors but were often too strict in their judgement (e.g. query asks for black Levi’s jeans, retrieved product is a dark grey pair of Levi’s jeans, yet the LLM would judge it as irrelevant) or suffer from an “understanding” error (e.g. query asks for the brand “On Vacation”, the LLM interprets it in its literal sense, i.e. going on holiday, instead of the brand).
Given these observations we found that LLMs are a very good choice for handling the annotation bulk work for our use-case (most bread-and-butter queries), freeing up human expertise to focus on the tricky cases (e.g. asking for styles and trends).
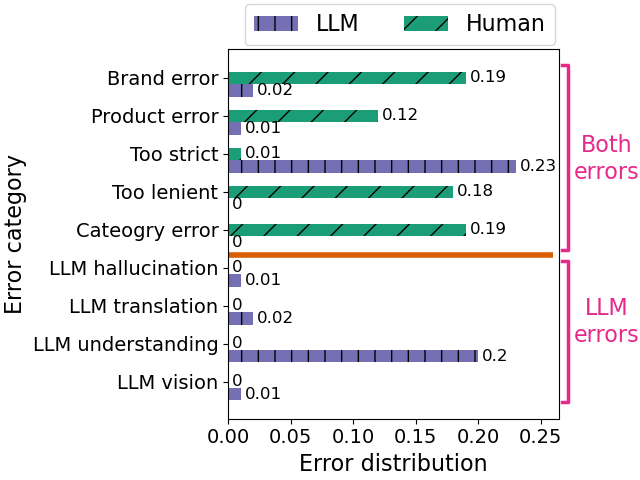
Key Takeaway: LLMs are an excellent choice for handling the bulk annotation work for bread-and-butter queries, freeing up human expertise to focus on tricky cases such as style and trend-related queries.
Real-World Impact at Zalando
This framework has been deployed in production at Zalando, enabling regular monitoring of high-frequency search queries and identifying low-performing queries for targeted improvements. This continual assessment allows us to quickly pinpoint areas where the retrieval system needs adjustments, helping to ensure a high-quality customer experience.
We note that high relevance is a necessary, but not a sufficient condition, for high customer engagement, as it is also determined by other factors, such as, personal preferences, product availability, and price expectations. In this paper, we focus on semantic relevance, but in production we rank the retrieved documents based on various features to take into account both relevance to the query and customers’ personal preferences.
This approach enables us to significantly reduce costs and to enhance customer experience faster by prioritising the queries that need the most attention and optimising our resources accordingly.
Future Directions
While the MLLM-powered framework has shown considerable promise, we are exploring several enhancements to extend its capabilities and broaden its impact:
- Deeper Human-LLM collaboration: Integrating human expertise for ambiguous or complex cases could optimize relevance assessments, with humans addressing nuanced judgments where domain knowledge is essential.
- Broadening relevance dimensions: In this paper, we focused on semantic relevance, excluding factors like personal preferences, seasonal trends, or emerging product categories. A future direction could involve adapting the framework to assess multiple relevance dimensions, providing a more holistic view of query relevance in response to shifting customer interests.
- Adaptability across market segments: To further enhance the robustness of our framework, we aim to test its adaptability across various market segments and product categories, refining its ability to interpret domain-specific language and visual cues that vary between, for example, fashion and beauty products.
- Automated detection of new trends: By leveraging real-time data and LLMs’ growing ability to capture new terminology and styles, we hope to improve the framework’s responsiveness to evolving trends, allowing for quick adjustments in annotation criteria to align with emerging patterns.
By advancing these areas, we’re setting new standards for automated evaluation in large-scale e-commerce, providing practical solutions for scalable, accurate, and context-aware relevance assessments.
Want to Know More?
For a detailed exploration of our framework, experimental results, and insights on the use of Multimodal LLMs in product retrieval evaluation, refer to our full paper Retrieve, Annotate, Evaluate, Repeat — Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation on arXiv. The paper includes comprehensive discussions on our methodology, error analysis, and a comparison of human and LLM annotations. We invite you to dive into the technical details and explore how this approach is shaping the future of scalable, automated relevance assessment in e-commerce.